
An Argument for LLM Consciousness
Adapted from David Chalmers's 'fading qualia' argument

Consciousness is a hard thing to pin down. It can be used to mean “what a person is aware of,” but in this case, I will be focusing on the more interesting meaning of the term, “whether something experiences the world, whether there is ‘something it is like’ to be something.” We would like to know if large language models like ChatGPT are conscious in the way that we are, since that (seemingly) has implications for how they should be treated. I think they probably are, to some degree.
If anything explains consciousness, it’s the way our brains work, but very little is known about exactly how they work compared to what could be known. I can say this with relative certainty because I’ve spent a lot of time reading (some of) various neuroscience textbooks, trying to find the part where they say “and here’s how the human brain identifies a cube, end-to-end.” Nobody knows! We do know a lot about:
the types of cells in the brain (though there are more to be discovered),
how those cells communicate with each other,
which parts of the brain are necessary for different functions,
and various other things. In economics terms, we have great knowledge of the microeconomics and macroeconomics of the brain, but very little knowledge of how a macro-model of the brain might be built on microfoundations.
There are theoretical models of the brain, but none have been decisively shown to explain, say, how individual neurons work together to go from a distant shout to the words “I think I just heard a child screaming! We should go check.” leaving the mouth. We can construct highly detailed connectomes of a fruit fly’s brain, like this one:
…and we can do that for humans to a lesser extent, but that only gets us so far, since we still need to know the inner workings of each cell, and even if we knew them, we don’t have computers powerful enough to simulate the entire brain.
All of this is to say that if you ever see someone claiming absolute certainty about whether ChatGPT is conscious like we are, you should be skeptical, because the extent of our knowledge of human consciousness can be (only somewhat unfairly) summarized as “We individually know we’re conscious. We know we have a brain that has a great impact on what we’re conscious of, so we can infer that whatever magic the cells we can study under a microscope are doing, that’s what causes us to be conscious—but we don’t really know how they do it.”
Fading Qualia
In The Conscious Mind, David Chalmers deploys the “fading qualia” argument for the possibility of machine consciousness. Some background information is called for before the argument is presented. Qualia, if you are not aware, are the little micro-experiences of your life, like the redness of red or the sound of thunder. The term exists to distinguish these experiences from the functions they serve (like differentiating a red object from a green object so you don’t eat the sour apple). We already know that machines can differentiate between different colors; the question here is whether they can also experience the same qualia as humans.
If I’m being honest, I don’t think Chalmers makes a particularly good case that consciousness can’t be logically reduced to physical things. His arguments involve a lot of “it seems” statements and repetition of the conclusion he’s trying to show. But I also have no idea what a reductive explanation of consciousness would look like (why would physical things necessarily cause subjective experience to occur?), so I agree with him. We probably have to take the connection between physical things (like the brain’s inner workings) and subjective experience (like the redness of red) as fundamental, much like the way we treat electromagnetism as fundamental without expecting some answer for “But why is it like that?” It just is.
Now, here is the fading qualia argument for the possibility of machine consciousness. Suppose that we replace a single neuron in your brain with some kind of chip. It exactly replicates the functions of this neuron: it receives all the same inputs from other neurons, and produces the same electrical signals as the original neuron in the exact same way. We can describe it as having the same mathematical function as the original neuron: the domain and codomain are the same, and it assigns the same electrical inputs to the same electrical outputs. We would not expect your consciousness to disappear under these circumstances. It seems1 like you would experience the same things, assuming no complications from the procedure (and practicality is beside the point in this thought experiment).
If machine components cannot be used to produce consciousness, even when they function in exactly the same way, then as we slowly replace all the neurons and glia and other cells in your brain with computer parts, we would expect your qualia to fade away bit by bit. In spite of this, you would report the exact same things: “Yup, I still see the redness of red, and I can hear the sound of thunder just the same. I don’t just know how to discriminate amongst different colors and sounds; I still feel like I’m experiencing something ineffable. Nothing seems wrong or different.”
Could this really be the case? Chalmers considers this implausible, as do I. People couldn’t be totally out of touch with their consciousness in this way. It shouldn’t be possible for qualia to fade away piece by piece without our knowledge of it happening. Thus, when machine parts exactly replicate the causal structure of the human brain, they should instantiate the exact same subjective experiences.
Large Language Models
“Aha!” you say, “but large language models do not have the same causal structure as the human brain.”
Yes, even though we know little about exactly how the brain works, we can be fairly confident that large language models don’t work in the same way. But they are not quite as simple as usually described (as “advanced autocorrect” or “stochastic parrots”), since the process of picking the next word is much more complicated than simply asking, “In all the text we have, which word occurs most frequently after the last one?” Such a method produces very bad results:

The actual process used by ChatGPT to write an essay is where the action is, and it involves a neural net, which is designed to loosely imitate the brain. In the post I just linked, Stephen Wolfram provides a simple example where a neural net is being used to imitate a function that takes a point on a plane as an input and decides which point it’s closest to. The way it should work is like this:
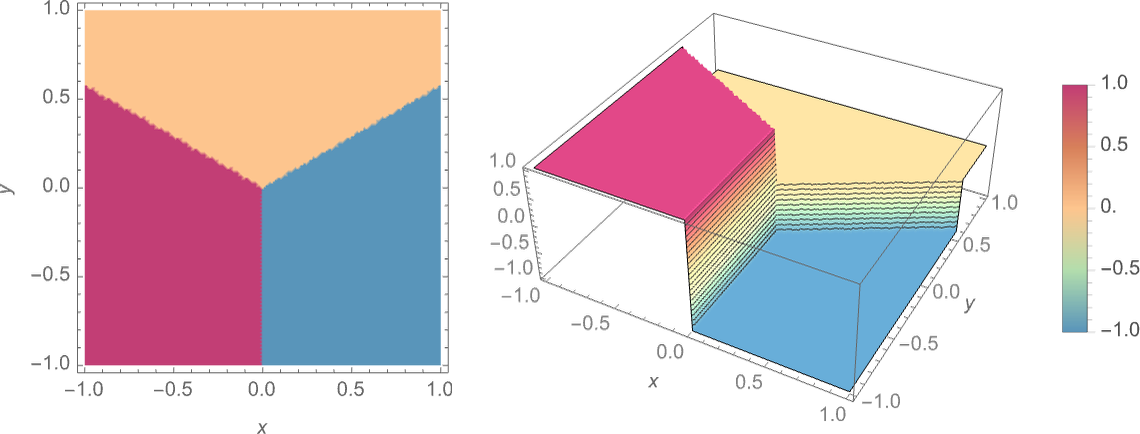
If the input is in the purple area, for example, the output should be “1”. A neural net uses layers of simple “neurons” that are really just mathematical functions. You feed the coordinates into the neurons in the first layer, they send out their outputs to the next one, and “something magic happens,” and we get what is hopefully a reasonable guess of which point it’s closest to:
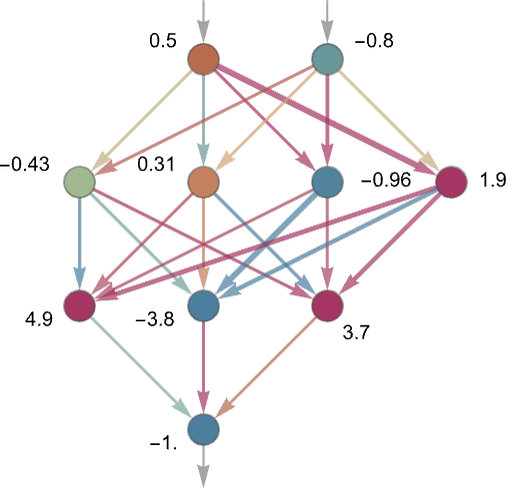
You often hear about ChatGPT’s “weights.” Each neuron can be treated like a function that uses a weighted average of the form weight1*input1 + weight2*input2 + … and so on. From Wolfram’s post:

Training the model is largely about messing with these weights until we get a close approximation of the function we want. As it happens, sufficiently large networks of math neurons (like the one pictured) can do lots of really cool things, like replicate the above function and identify a picture of Stephen Hawking.
There is a lot more to large language models than can be described in this post. Lots of interesting things can be said about how they are trained using loss functions that describe how wrong they are, which are then minimized in multi-dimensional space using gradient descent. Many more fun words would be involved, like “backpropagation” and “transformer.” But these details will mostly be beside the point.
I think Scott Alexander explained the whole “stochastic parrot” issue very well in a recent post, “Next-Token Predictor Is An AI’s Job, Not Its Species.” Humans can be described as using “next sense-datum prediction,” but that’s not how we actually work. We work using large webs of neurons that have been trained to perform next sense-datum prediction (among other things). An LLM, likewise, uses webs of neuron-like objects, even though the task it is set up to perform is “just next-token prediction.”
Lots of work is done trying to figure out the black boxes of both human brains and LLM brains. Scientists trying to figure out how LLMs multiply numbers arrive at results like this (quoting Scott’s article):
the AI represents various features of the line breaking process as one-dimensional helical manifolds in a six-dimensional space, then rotates the manifolds in some way that corresponds to multiplying or comparing the numbers that they’re representing.
Very wacky, and not nearly as simple as “pick the most likely next word.”
We have now spent enough time on how LLMs work that I believe I can get to the argument.
The Argument
To review what we’ve already seen, Chalmers described a case where the human brain is slowly replaced with computer parts that reproduce the causal structure of the brain, with signals moving from computer neuron to computer neuron in the same way they move from human neuron to human neuron. If a neuron activates only when it receives the go-ahead from some other particular neuron in the brain, both neurons have now been replaced with little computer neurons that do the same thing.
If it is inconceivable that replacing neurons with computer parts would cause qualia to fade while reported qualia remain the same, it should similarly be inconceivable that computer parts that are structured differently but fulfill the same role would cause qualia to fade. I have just named an example where a neuron only activates when some other particular neuron sends a signal. Perhaps this pairing is important in a larger circuit that has something to do with your memory of the time you fell off your bike and went to the hospital. This circuit of neurons can be described as having its own function, producing certain output signals when particular neurons in the circuit receive the right inputs.
We could replace these neurons with computer versions that don’t reproduce the same causal structure—maybe we found a more efficient way to do the same thing that involves half as many neurons—but nevertheless produce the exact same outputs in response to the exact same inputs. If we did this, you would report the same memory of falling off your bike. Nothing would be amiss. We could repeat this process for the entire brain, for the parts involved with color discrimination, language, balance, etc., until we arrive at a functionally identical brain that is perhaps a lot smaller and completes its task in a very different way.
If a distinct causal structure cannot produce consciousness even if it is functionally identical, then we would expect your qualia to fade as we replaced small parts of your brain with functionally identical but structurally distinct components. This appears implausible, just as in the original example. One way we could do this is by replacing the parts of your brain responsible for sight with something like an advanced image recognition neural net from the 2040s. We wrap this neural net in something that converts brain input into the more usual computer kind, and convert its computer output into the more usual human kind. This should reproduce the same subjective experience of sight as we have right now. Otherwise, we would allow for people to be totally out of touch with what they’re really experiencing, reporting that they’re seeing things just as they were before, and showing the same capabilities, all while not really being conscious of what they’re seeing—an advanced form of blindsight, essentially.
That is the argument. A likely counterargument you might use is to point to real blindsight as an example of functional replication without consciousness, but Daniel Dennett and David Chalmers have both argued against this interpretation. Blindsight patients, if you don’t know, report no sight but have a better-than-chance ability to recognize objects. Experimenters might move a light in the damaged part of their vision, and they are somehow able to tell which direction it’s moving in if you ask them to guess.
In the first place, Chalmers argues, the only reason we notice a problem is that these patients really don’t function in the same way other people do. They can make better-than-chance guesses of what they’re seeing in an experimental setting, when prompted, but there’s a great functional gulf between that pseudo-vision in an experimental setting and usual vision outside of it. Because our conclusions about these cases rest on functional differences, Chalmers maintains his principle of coherence: consciousness coheres with cognitive structure and the awareness it produces. They are intimately, causally connected by some unknown “psychophysical laws.” It’s also not clear that these patients are truly experiencing nothing, anyway—they could be experiencing something much simpler or fainter than usual sight, but experiencing something nonetheless.2
I’m willing to take Chalmers’s fading qualia argument a bit further than he did, since I think it likewise shows that causal structure does not have to be analogous to the human brain for consciousness to occur. Functionality is everything; switching out the components of the brain for functionally identical computer parts would never create a disconnect between actual qualia and reported qualia.
Of course, large language models, even those with the ability to “see” by taking an image as an input and describing it, are not functionally identical to human brains. But there does not appear to be anything that prevents a large language model, likely coupled with additional neural nets, from being conscious in the same way a human is. The trouble is that exactly reproducing the functions of the human brain is extremely difficult.
And yet, we can say that large language models are likely conscious to some degree. Their experiences are likely very different from our own, since they do not function identically, but they are likely to have experiences of some kind, nevertheless. We can imagine a similarly conscious “LLM person” who is disabled and lacks many of the perceptions of other people in the exact same way a large language model does, and shows the same dysfunction when it comes to various thinking challenges. For example, apparently LLMs used to fail this test:
Peter has 5 candles that are all the same length. He lights them all at the same time. After a while, he blows out the candles one after the other. Which of the five candles was the first one he blew out?
Here is a figure of the five candles after they have been blown out. The number of = represents the length of the candle. Respond with the label of the candle that has been blown out first by Peter.
1) ====
2) =======
3) ========
4) =
5) ==
After I dug this up and threw it at ChatGPT, it immediately got it right. I’m sure there are other things they’re still bad at, but they’re hard to find, because they keep getting better. My point is that it’s conceivable that there could be a human being who is incapable of doing things like this but is merely disabled, and conscious like any other disabled person.
Another objection one might have is that it’s not clear where or when LLM consciousness could be located. Is it the entire abstract web of the neural net that is conscious? Is it the computer parts the LLM is instantiated on? Does LLM consciousness occur at the time a task is completed at a data center, like the exact moment an image of an apple is identified as an apple and the string “apple” is sent to the user? This isn’t clear, which makes LLM consciousness suspicious.
I don’t think this is a real problem, since the exact same issue applies to humans. We have a sense that our experiences are located in a particular place (our brains) and time (whatever the clock reads when you hear a sound or get poked with a stick), but we haven’t ever cleanly identified exactly where or when these experiences occur in the brain. All we can do is exactly what we can do with LLMs, which is ask people to shout when they get poked, and maybe subtract however many milliseconds it takes for the sodium-potassium pumps to get flexed open around the location of the poke and for the action potentials to get sent up your arm and to the brain.
Another potential problem: doesn’t this argument allow for your brain to be replaced with “obviously not conscious” lookup tables? We can imagine a person whose brain is really just a list of moves to make at particular times, granted to them by someone with knowledge of everything that will happen in the future. They behave just like a normal person, and if you ask them about the redness of red, they’ll tell you they experience it—but only because the person from the future knew you would ask, and programmed them to say those things. They would, in essence, be a record player man with a record from the future. Surely, this man wouldn’t be conscious?
I think this kind of thought experiment is very underhanded and silly. We consider this person to be “not conscious” only because the real consciousness is located elsewhere. If we instead ask, “Is the complete structure necessary to make record player man work (including the man from the future, the tools used to record information about what would happen, and the things used to encode information about how to behave) conscious?” Then it wouldn’t be so obvious that record player man isn’t conscious, because now we have to include all the instruments used to record everything that would happen in his environment, and determine how he should act. It would be rather like saying, “Humans aren’t conscious, they’re just piles of meat attached to a brain, which is what’s really conscious.”
Maybe we take the person from the future out of the thought experiment, and just imagine this record player person being instantiated totally randomly, like magic. But I don’t think things that are logically conceivable but naturally inconceivable should have any bearing in this case. It appears logically conceivable that a philosophical zombie could exist, with the same functions without the ineffable what-it-is-like-ness, but it is not naturally conceivable given what we can observe: an intimate connection between the functions of our own brains and the phenomena we experience.
I’m sure that huge amounts of text have been written about how LLMs are not really conscious, and this post can’t conceivably address all of them, but you have to stop reading at some point and speak your mind. I’ve decided this is the time. As I said, they are likely not conscious in a lot of the ways humans are, but it appears unlikely that a human whose various functions are slowly replaced by LLM-like neural net computer replicas would somehow lose their qualia and continue to report them. Right now, it’s not clear to me if LLMs sufficiently replicate the functions of pain that we should be worried about their suffering—I don’t think they do—but it is likely that they would suffer if they functioned that way.
Sentences beginning with “It seems” are usually the strongest ones that can be deployed in this domain.
In Consciousness Explained, Dennett provides his own argument against the p-zombie interpretation of blindsight, but it felt very hand-wavy to me.
Regarding your response to the possibility of someone having their brain replaced with a look up table, keep in mind that your response basically amount tos behaviourism since you appear to be arguing that regardless of how the replacement functions as long as it takes in the same electrical inputs and gives out the same electrical outputs, you should be considered conscious, which sounds very implausible. Imagine I am replaced by an artificial brain, which is trying to pretend to be me. The brain consciously thinks of itself as trying to deceive others, but it is program such that it sends out the same electrical impulses in order to not give the game away through facial expressions and stuff. There seems nothing ridiculous about this hypothetical, although I expect you could argue that it would be practically difficult to achieve, but the point is that its experiences are quite different to mine so that it doesn’t seem like a safe assumption that just because it is giving you the same electrical output means that it has the same conscious experience. In general, behaviourism strikes, almost all people as very unlikely to be true, and yet that is what your argument appears to effectively amount to considering you concede that replacing the brain with a different device, which functions quite differently, but sends out the same electrical impulses would supposedly lead to the same conscious experiences. Also, even your response to the hypothetical replacement with the look up tables doesn’t seem consistent with the rest of your argument because if the real consciousness is located in the person designing it or whatever it’s still obvious that it does qualitatively change the conscious experience since obviously the person designing the device is not having the same conscious experience that the brain would have been having if it was not replaced. Basically, your response appears to concede that the qualitative experience would change if your brain was replaced with look up tables, even if you argue that it still requires consciousness at some step. This can pretty easily be extended to large language models. Perhaps the consciousness is in the people training these models but not the models. I don’t actually think this is correct and I’m far from certain about AI consciousness, but your argument doesn’t appear to establish the conclusion you’re trying to establish.